from fastai.vision.all import *
path = untar_data(URLs.PETS)A Journey Through Fastbook (AJTFB) - Chapter 5: Multiclass classification
fastai
fastbook
multiclass classification
computer vision
Its the image classification chapter of "Deep Learning for Coders with fastai & PyTorch"! We’ll go over everything you need to know to get started with multiclass classification, from setting up your DataBlock and loss function, to some of the core techniques for evaluating and improving your model’s predictions. So without further adieu, lets go …
Other posts in this series:
A Journey Through Fastbook (AJTFB) - Chapter 1
A Journey Through Fastbook (AJTFB) - Chapter 2
A Journey Through Fastbook (AJTFB) - Chapter 3
A Journey Through Fastbook (AJTFB) - Chapter 4
A Journey Through Fastbook (AJTFB) - Chapter 6a
A Journey Through Fastbook (AJTFB) - Chapter 6b
A Journey Through Fastbook (AJTFB) - Chapter 7
A Journey Through Fastbook (AJTFB) - Chapter 8
A Journey Through Fastbook (AJTFB) - Chapter 9
Multiclass vs Multi-label classification …
Yah, it can be confusing!
Anyhow, multiclass classification is all about predicting a SINGLE CLASS an object belongs to from a list of two or more classes. It can be a simple as predicting whether an image is a dog or a cat, or as complex as predicting the breed of dog from amongst dozens of potential breeds.
Multi-label classification (covered in the next chapter) involves predicting MULTIPLE CLASSES to which an object belongs; it can belong to one, some, all, or even none of those classes. For example, you may be looking at satellite photos from which you need to predict the different kinds of terrain (your classes) each contains.
Defining your DataBlock
Again, the DataBlock is a blueprint for everything required to turn your raw data (images and labels) into something that can be fed through a neural network (DataLoaders with a numerical representation of both your images and labels). Below is the one presented in this chapter.
dblock = DataBlock(blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
get_y=using_attr(RegexLabeller(r'(.+)_\d+.jpg$'), 'name'),
splitter=RandomSplitter(seed=42),
item_tfms=Resize(460),
batch_tfms=aug_transforms(size=224, min_scale=.75))Let’s break down our blueprint!
- Define the data types for our inputs and targets via the
blocksargument.
This is defined as a tuple, where we tell our DataBlock that the imputs are images and our targets are a single category (or class or label).
- Define how we’re going to get our raw data via
get_items.
We use get_image_files because we are getting image files from the filesystem. When we kick off the DataBlock to build our DataLoaders, we’ll pass in the path to our images which will in turn be passed to get_image_files to pull the raw data.
- Define how, from the raw data, we’re going to create our labels (e.g., the classes for each image) via
get_y.
In this case, we don’t need to define a get_x because get_items gets the x’s already. However, since we are working with filenames from which we want to define our labels, we do need this fancy get_y function above. using_attr tells the RegexLabeller what attribute of our data to apply itself too, and since our data is filenames, we tell it to use the .name property of each filename object as the thing the RegexLabeller acts against. That will give us our target class.
Define how we’re going to create our validation dataset via
splitterDefine things we want to do for each item via
item_tfms
item_tfms are transforms, or things we want to do, to each input individually! Above we only have one which says, “Resize each image to 460 max width/height” one by one when we grab it. For individual images to be collated into mini-batches, they have to be the same size … thus we do this here and not below.
- Define things we want to do for each mini-batch of items via
batch_tfms
batch_tfms are transforms, or things we want to do, to a mini-batch of inputs at once on the GPU. aug_transforms includes a bunch that have proven to be effective in computer vision tasks. With the parameters we’re passing into it above (size=224, min_scale=.75), we’re saying, “Take the mini-batch of images here and randomly crop the 460x460 images to be 224x224 that captures at least 3/4 of the image”. See here for more info on RandomResizedCrop.
Important
If you can describe your DataBlock like I have above, you understand it!
Important
Verify your DataBlock works as expected, or else troubleshoot it, by running DataBlock.summary(data)
dblock.summary(path/'images')Setting-up type transforms pipelines
Collecting items from /root/.fastai/data/oxford-iiit-pet/images
Found 7390 items
2 datasets of sizes 5912,1478
Setting up Pipeline: PILBase.create
Setting up Pipeline: partial -> Categorize -- {'vocab': None, 'sort': True, 'add_na': False}
Building one sample
Pipeline: PILBase.create
starting from
/root/.fastai/data/oxford-iiit-pet/images/Bombay_111.jpg
applying PILBase.create gives
PILImage mode=RGB size=604x453
Pipeline: partial -> Categorize -- {'vocab': None, 'sort': True, 'add_na': False}
starting from
/root/.fastai/data/oxford-iiit-pet/images/Bombay_111.jpg
applying partial gives
Bombay
applying Categorize -- {'vocab': None, 'sort': True, 'add_na': False} gives
TensorCategory(3)
Final sample: (PILImage mode=RGB size=604x453, TensorCategory(3))
Collecting items from /root/.fastai/data/oxford-iiit-pet/images
Found 7390 items
2 datasets of sizes 5912,1478
Setting up Pipeline: PILBase.create
Setting up Pipeline: partial -> Categorize -- {'vocab': None, 'sort': True, 'add_na': False}
Setting up after_item: Pipeline: Resize -- {'size': (460, 460), 'method': 'crop', 'pad_mode': 'reflection', 'resamples': (2, 0), 'p': 1.0} -> ToTensor
Setting up before_batch: Pipeline:
Setting up after_batch: Pipeline: IntToFloatTensor -- {'div': 255.0, 'div_mask': 1} -> Flip -- {'size': None, 'mode': 'bilinear', 'pad_mode': 'reflection', 'mode_mask': 'nearest', 'align_corners': True, 'p': 0.5} -> RandomResizedCropGPU -- {'size': (224, 224), 'min_scale': 0.75, 'ratio': (1, 1), 'mode': 'bilinear', 'valid_scale': 1.0, 'max_scale': 1.0, 'p': 1.0} -> Brightness -- {'max_lighting': 0.2, 'p': 1.0, 'draw': None, 'batch': False}
Building one batch
Applying item_tfms to the first sample:
Pipeline: Resize -- {'size': (460, 460), 'method': 'crop', 'pad_mode': 'reflection', 'resamples': (2, 0), 'p': 1.0} -> ToTensor
starting from
(PILImage mode=RGB size=604x453, TensorCategory(3))
applying Resize -- {'size': (460, 460), 'method': 'crop', 'pad_mode': 'reflection', 'resamples': (2, 0), 'p': 1.0} gives
(PILImage mode=RGB size=460x460, TensorCategory(3))
applying ToTensor gives
(TensorImage of size 3x460x460, TensorCategory(3))
Adding the next 3 samples
No before_batch transform to apply
Collating items in a batch
Applying batch_tfms to the batch built
Pipeline: IntToFloatTensor -- {'div': 255.0, 'div_mask': 1} -> Flip -- {'size': None, 'mode': 'bilinear', 'pad_mode': 'reflection', 'mode_mask': 'nearest', 'align_corners': True, 'p': 0.5} -> RandomResizedCropGPU -- {'size': (224, 224), 'min_scale': 0.75, 'ratio': (1, 1), 'mode': 'bilinear', 'valid_scale': 1.0, 'max_scale': 1.0, 'p': 1.0} -> Brightness -- {'max_lighting': 0.2, 'p': 1.0, 'draw': None, 'batch': False}
starting from
(TensorImage of size 4x3x460x460, TensorCategory([ 3, 17, 10, 4], device='cuda:0'))
applying IntToFloatTensor -- {'div': 255.0, 'div_mask': 1} gives
(TensorImage of size 4x3x460x460, TensorCategory([ 3, 17, 10, 4], device='cuda:0'))
applying Flip -- {'size': None, 'mode': 'bilinear', 'pad_mode': 'reflection', 'mode_mask': 'nearest', 'align_corners': True, 'p': 0.5} gives
(TensorImage of size 4x3x460x460, TensorCategory([ 3, 17, 10, 4], device='cuda:0'))
applying RandomResizedCropGPU -- {'size': (224, 224), 'min_scale': 0.75, 'ratio': (1, 1), 'mode': 'bilinear', 'valid_scale': 1.0, 'max_scale': 1.0, 'p': 1.0} gives
(TensorImage of size 4x3x224x224, TensorCategory([ 3, 17, 10, 4], device='cuda:0'))
applying Brightness -- {'max_lighting': 0.2, 'p': 1.0, 'draw': None, 'batch': False} gives
(TensorImage of size 4x3x224x224, TensorCategory([ 3, 17, 10, 4], device='cuda:0'))Now we can create our DataLoaders and take a look at our x’s and y’s, our pet images and their label/class
dls = dblock.dataloaders(path/'images')
dls.show_batch()
To get a feel for what our batch_tfms are doing, we can show_batch using a single image as we do below.
dls.show_batch(unique=True)
The combination of what we’re doing in the item_tfms and batch_tfms is known as presizing.
“Presizing is a particular way to do iamge augmentation taht is designed to minimize data destruction while maintaining good performance.” After resizing all the images to a larger dimension that we will train on, we perform all our core augmentations on the GPU. This results in both faster and less destructive transformations of the data.
Important
See pp190-191 for how these augmentations are applied to the training and validation set!
Train a model
Important
“Once you think your data looks right, we generally recommend the next step should be using it to train a simple model” See bottom of p193 for why.
Define your loss function
To train a model we need a good loss function that will allow us to optimize the parameters of our model. For multiclassification tasks where we want to predict a single class/label, to go to is cross-entropy loss
To understand how this particular loss function operates and its interesting effects, see my prior article “Loss Functions: Cross Entropy Loss and You!” It’s all about how it works, why use it over something like accuracy, and so forth. Pages 194-203 is the place to look in fastbook for more details on the ins and outs of this loss function.
Important
Cross-entropy loss is the Highlander of loss functions … “there can only be one”
“Intuitively, the softmax function really wants to pick one class … so it’s ideal for training a classifier when we know each piecture has a definite label. (Note taht it may be less ideal during inference, as you might want your model to sometimes tell you it doesn’t recognize any of the classes taht is has seen during training, and not pick a class because it has a slightly bigger activation score. In this case, it might be better to train a model using multiple binary output columns, each using a sigmoid activation.)”
Train a model
learn = cnn_learner(dls, resnet34, metrics=error_rate)
Important
Use the Learning Rate Finder to determine a good LR to use during the optimization step!
“One of the most importatn things we can do when training a model is to make sure that we have the right learning rate. If our learning rate is too low, it can take many, many epochs to train our model … also that we may have problems with overfitting, ceacuse every time we do a complete pass through the data, we give our model a chance to memorize it”
See p 205-206 for more information on how it works, and also Leslie Smith’s paper on it here. A must read for fastai developers!!!
lr_min, lr_steep = learn.lr_find()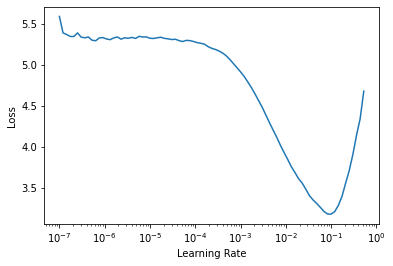
lr_min, lr_steep(0.010000000149011612, 0.0063095735386013985)
Important
Pick either “one order of magnitude less that where the minimum loss was achieved” (lr_min above, which is actually the true minimum, roughly 1e-1 / 10, 0.01 or else 1e-2) -or- “the last point where the loss was clearly decreasing”
These two are likely close to one another, and if you’re not sure which to use, try them both!
learn.fine_tune(2, base_lr=1e-2)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.988194 | 0.477657 | 0.131258 | 01:05 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.990748 | 0.932280 | 0.228687 | 01:09 |
| 1 | 0.537608 | 0.289773 | 0.089986 | 01:07 |
Using fine_tune gives us a nice and quick baseline we can look back at going forward. Nevertheless, we can likely improve our model by taking more control over what parameters are trained (updated), when, and by how much using fit_one_cycle.
So let’s start again, by defining our Learner and finding a good LR for training ONLY the last layer’s parameters (the idea being that the pretrained model we’re finetuning, our backbone, is already pretty good at understanding images … while the last layer’s parameters are random because they are specific to our task at hand).
learn = cnn_learner(dls, resnet34, metrics=error_rate)
lr_min, lr_steep = learn.lr_find()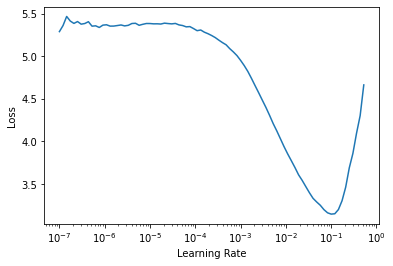
learn.fit_one_cycle(2, lr_max=1e-2)| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.094374 | 0.674852 | 0.180650 | 01:05 |
| 1 | 0.645389 | 0.303023 | 0.096752 | 01:03 |
NOW … we’re going to “unfreeze” our model, meaning we’re going to make all the parameters trainable. And then we’re going to apply discriminative learning rates, or different base LRs to different parts of our models, with the assumption that earlier layers likely only need to change a little while later layers, especially our classification head, have to change more. This is covered thoroughly in another must read paper, Universal Language Model Fine-tuning for Text Classification
Look at the bottom of the cell below’s output to see the number of traininable parameters for our currently frozen model.
learn.summary()Sequential (Input shape: 64)
============================================================================
Layer (type) Output Shape Param # Trainable
============================================================================
64 x 64 x 112 x 112
Conv2d 9408 False
BatchNorm2d 128 True
ReLU
MaxPool2d
Conv2d 36864 False
BatchNorm2d 128 True
ReLU
Conv2d 36864 False
BatchNorm2d 128 True
Conv2d 36864 False
BatchNorm2d 128 True
ReLU
Conv2d 36864 False
BatchNorm2d 128 True
Conv2d 36864 False
BatchNorm2d 128 True
ReLU
Conv2d 36864 False
BatchNorm2d 128 True
____________________________________________________________________________
64 x 128 x 28 x 28
Conv2d 73728 False
BatchNorm2d 256 True
ReLU
Conv2d 147456 False
BatchNorm2d 256 True
Conv2d 8192 False
BatchNorm2d 256 True
Conv2d 147456 False
BatchNorm2d 256 True
ReLU
Conv2d 147456 False
BatchNorm2d 256 True
Conv2d 147456 False
BatchNorm2d 256 True
ReLU
Conv2d 147456 False
BatchNorm2d 256 True
Conv2d 147456 False
BatchNorm2d 256 True
ReLU
Conv2d 147456 False
BatchNorm2d 256 True
____________________________________________________________________________
64 x 256 x 14 x 14
Conv2d 294912 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
Conv2d 32768 False
BatchNorm2d 512 True
Conv2d 589824 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
Conv2d 589824 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
Conv2d 589824 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
Conv2d 589824 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
Conv2d 589824 False
BatchNorm2d 512 True
ReLU
Conv2d 589824 False
BatchNorm2d 512 True
____________________________________________________________________________
64 x 512 x 7 x 7
Conv2d 1179648 False
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 False
BatchNorm2d 1024 True
Conv2d 131072 False
BatchNorm2d 1024 True
Conv2d 2359296 False
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 False
BatchNorm2d 1024 True
Conv2d 2359296 False
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 False
BatchNorm2d 1024 True
____________________________________________________________________________
[]
AdaptiveAvgPool2d
AdaptiveMaxPool2d
Flatten
BatchNorm1d 2048 True
Dropout
____________________________________________________________________________
64 x 512
Linear 524288 True
ReLU
BatchNorm1d 1024 True
Dropout
____________________________________________________________________________
64 x 37
Linear 18944 True
____________________________________________________________________________
Total params: 21,830,976
Total trainable params: 563,328
Total non-trainable params: 21,267,648
Optimizer used: <function Adam at 0x7fe0e7fb57a0>
Loss function: FlattenedLoss of CrossEntropyLoss()
Model frozen up to parameter group #2
Callbacks:
- TrainEvalCallback
- Recorder
- ProgressCallbackLet’s unfreeze and look at the same …
learn.unfreeze()
learn.summary()Sequential (Input shape: 64)
============================================================================
Layer (type) Output Shape Param # Trainable
============================================================================
64 x 64 x 112 x 112
Conv2d 9408 True
BatchNorm2d 128 True
ReLU
MaxPool2d
Conv2d 36864 True
BatchNorm2d 128 True
ReLU
Conv2d 36864 True
BatchNorm2d 128 True
Conv2d 36864 True
BatchNorm2d 128 True
ReLU
Conv2d 36864 True
BatchNorm2d 128 True
Conv2d 36864 True
BatchNorm2d 128 True
ReLU
Conv2d 36864 True
BatchNorm2d 128 True
____________________________________________________________________________
64 x 128 x 28 x 28
Conv2d 73728 True
BatchNorm2d 256 True
ReLU
Conv2d 147456 True
BatchNorm2d 256 True
Conv2d 8192 True
BatchNorm2d 256 True
Conv2d 147456 True
BatchNorm2d 256 True
ReLU
Conv2d 147456 True
BatchNorm2d 256 True
Conv2d 147456 True
BatchNorm2d 256 True
ReLU
Conv2d 147456 True
BatchNorm2d 256 True
Conv2d 147456 True
BatchNorm2d 256 True
ReLU
Conv2d 147456 True
BatchNorm2d 256 True
____________________________________________________________________________
64 x 256 x 14 x 14
Conv2d 294912 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
Conv2d 32768 True
BatchNorm2d 512 True
Conv2d 589824 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
Conv2d 589824 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
Conv2d 589824 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
Conv2d 589824 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
Conv2d 589824 True
BatchNorm2d 512 True
ReLU
Conv2d 589824 True
BatchNorm2d 512 True
____________________________________________________________________________
64 x 512 x 7 x 7
Conv2d 1179648 True
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 True
BatchNorm2d 1024 True
Conv2d 131072 True
BatchNorm2d 1024 True
Conv2d 2359296 True
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 True
BatchNorm2d 1024 True
Conv2d 2359296 True
BatchNorm2d 1024 True
ReLU
Conv2d 2359296 True
BatchNorm2d 1024 True
____________________________________________________________________________
[]
AdaptiveAvgPool2d
AdaptiveMaxPool2d
Flatten
BatchNorm1d 2048 True
Dropout
____________________________________________________________________________
64 x 512
Linear 524288 True
ReLU
BatchNorm1d 1024 True
Dropout
____________________________________________________________________________
64 x 37
Linear 18944 True
____________________________________________________________________________
Total params: 21,830,976
Total trainable params: 21,830,976
Total non-trainable params: 0
Optimizer used: <function Adam at 0x7fe0e7fb57a0>
Loss function: FlattenedLoss of CrossEntropyLoss()
Model unfrozen
Callbacks:
- TrainEvalCallback
- Recorder
- ProgressCallback… and as you can see, we’re training everything!
Because what parameters were training has changed, we also need to run the LR finder again to get some guidance on how to set our LRs.
lr_min, lr_steep = learn.lr_find()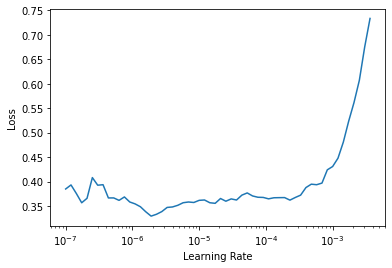
So lets see how many parameter/layer groups we have
len(learn.opt.param_groups)3What we can now do is say, train the first layer group with an LR of 1e-6 … the last with an LR of 1e-4, and “the layers in between will have learning rates that are multiplicatively equidistnat throughout that range.” Since we only have 3, the middle group will be trained with a starting LR of 1e-5
Important
We usually choose the first number a bit back from where things start to go bad … and the last number 1-2 magnitudes lower than the base LR of the frozen model
learn.fit_one_cycle(12, lr_max=slice(1e-6, 1e-4))| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.394857 | 0.291812 | 0.091340 | 01:06 |
| 1 | 0.359788 | 0.266810 | 0.084574 | 01:05 |
| 2 | 0.315511 | 0.248843 | 0.078484 | 01:05 |
| 3 | 0.308508 | 0.245649 | 0.081191 | 01:06 |
| 4 | 0.272639 | 0.231762 | 0.077131 | 01:06 |
| 5 | 0.231295 | 0.222235 | 0.075778 | 01:06 |
| 6 | 0.216695 | 0.223222 | 0.077808 | 01:06 |
| 7 | 0.207144 | 0.226977 | 0.075778 | 01:07 |
| 8 | 0.191794 | 0.223768 | 0.075778 | 01:07 |
| 9 | 0.193688 | 0.222243 | 0.076455 | 01:07 |
| 10 | 0.185064 | 0.219272 | 0.076455 | 01:07 |
| 11 | 0.177980 | 0.221938 | 0.073072 | 01:07 |
learn.recorder.plot_loss()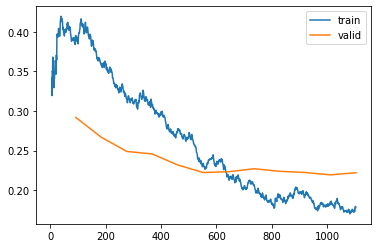
Important
Overfitting does not mean your model isn’t improving!
“You will often see that the accuracy continues improving, even as the validation loss gets worse. In the end, what matters is your accuracy [or your chosen metric], not the loss. The loss is just the function we’ve given the computer to help us to optimize”
How to choose the number of epochs?
Important
“Your first approach to training should be to simply pick a number of epochs that will train in the amount of time that you are happy to wait for.”
If the model is still getting better, then you haven’t trained your model long enough.
If your metric(s) are getting worse, “if you find that you have overfit, what you should do is retrain your model from scratch, and this time select a total number of epochs based on where your previous best results were found.”
When to choose a deeper architecture?
“A larger (more layers and parameters; sometimes described as the capacity of a model) version of ResNet will always be able to give us a better training loss, but it can suffer more from overfitting, because it has more parameters to overfit with. In general, a bigger model has the ability to better capture the real underlying relationships in your data, as well as to capture and memorize the specific details of your individual images.”
So consider these if … 1. You aren’t getting the results you need. 2. Have time to experiment and a big enough GPU to experiment with
You may need to reduce the size of your batches with these bigger models, and you can also us mixed-precision training, in order to get things to run on your GPU. The later results in faster training and gives you the ability to have bigger batch sizes than you would be able to support otherwise. All you need to do is add to_fp16() to your `Learner.
learn = cnn_learner(dls, resnet50, metrics=error_rate).to_fp16()
learn.fine_tune(6, freeze_epochs=1)Downloading: "https://download.pytorch.org/models/resnet50-19c8e357.pth" to /root/.cache/torch/hub/checkpoints/resnet50-19c8e357.pth| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.977287 | 0.299639 | 0.100812 | 01:06 |
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 0.371637 | 0.253767 | 0.080514 | 01:07 |
| 1 | 0.375325 | 0.300937 | 0.079161 | 01:07 |
| 2 | 0.281241 | 0.309774 | 0.089310 | 01:07 |
| 3 | 0.149089 | 0.216163 | 0.059540 | 01:07 |
| 4 | 0.093488 | 0.176675 | 0.054127 | 01:07 |
| 5 | 0.063744 | 0.169187 | 0.050744 | 01:07 |
Summary
Well, at this point, you know how to train a multiclassification computer vision task. So, go train one for yourself using what you’ve learned!
Make sure you understand and why we use cross-entropy loss for multiclassification problems. I can’t tell you how many times I’ve responded to questions about why someone’s model wasn’t training only to find out the reason was because they had the wrong loss function. Know it, love it, use it :)
Also, so much of what fastai incorporates from the LR finder and the fit_one_cycle, comes from Leslie Smith’s research. Checkout the “Resources” section below for some of his more influential papers, all of which I’ve read and encourage the rest of you to read if you want some inside scoop about why fastai works the way it does. I guarantee, reading and studying those papers will make you a better deep learning practioner and a better fastai developer in particular! You may think you’re not ready to start reading academic papers at chapter 5, but believe me, I’ve been there, and you are :)
Resources
https://book.fast.ai - The book’s website; it’s updated regularly with new content and recommendations from everything to GPUs to use, how to run things locally and on the cloud, etc…
Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates
Universal Language Model Fine-tuning for Text Classification